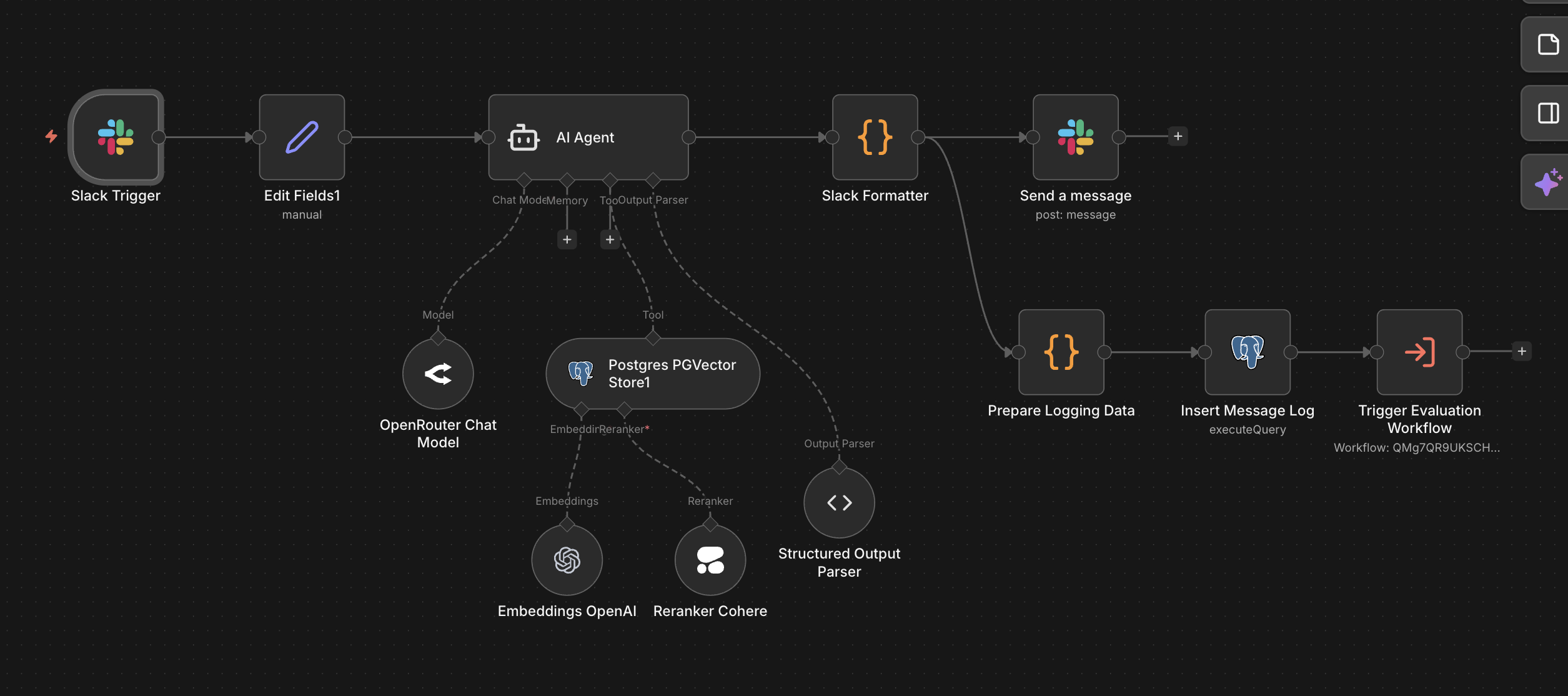
Juju 1.0 — n8n Workflow Canvas
FieldPulse's internal knowledge assistant. Custom RAG pipeline in production, now evolving to MCP-based architecture. 69.2% accuracy, ~30 messages/day, ~30 minutes saved per user per day.
Juju 1.0 — n8n Workflow Canvas
Context
FieldPulse serves thousands of contractors and tradespeople. Internally, the implementation and support teams fielded a constant stream of questions — how a specific feature worked, what a Confluence doc said, how to configure a workflow for a particular use case. Answers existed across Slack history, Notion pages, help center articles, and Confluence docs, but there was no institutional memory. Every lookup was a fresh search, and the cost was invisible until it started compounding.
Problem
Teams needed a way to query internal knowledge without interrupting each other. Help center articles lived in one system. Confluence docs lived in another. Neither was searchable in context — from where the work actually happened: Slack. The challenge went beyond basic retrieval. A bot that returned plausible-sounding wrong answers would erode trust faster than no bot at all. The system had to be honest about what it knew, cite its sources, and fail gracefully when it didn't have an answer.
Approach
Instead of building another tool nobody would adopt, I embedded the assistant directly in Slack. The decision was to own the full stack — chunking, embedding, retrieval, reranking, response generation — rather than reaching for a black-box SaaS layer. Full control at each stage made the system debuggable when things went wrong.
Document Ingestion
Chunked and embedded help center articles and Confluence docs into Supabase PGVector.
Cohere Reranking
Added a reranking layer to push the most relevant chunks to the top, significantly improving precision over raw cosine similarity.
n8n Orchestration
Wired the full pipeline in n8n: Slack trigger, query embedding, vector retrieval, reranking, LLM response generation, and Slack reply with source citations.
Evaluation Pipeline
Ran 30 production questions against multiple prompt variants and model configs. Scored for faithfulness, hallucination rate, and answer quality to select the best configuration.
Feedback & Monitoring
Thumbs up/down reactions tracked quality in production. A bug notification system fired Slack alerts on errors or flagged hallucinations in real time.
Architecture
Juju 1.0 was a fully custom RAG pipeline: document chunking, PGVector embeddings, Cohere reranking, n8n orchestration. It ran in production for five to six months, handling roughly 30 messages per day with ~50% daily adoption across three teams. It worked — but it created ongoing maintenance surface area: managing embeddings, handling Cohere free-tier limits, keeping the vector store in sync with changing docs, and dealing with model instability on OpenRouter.
Juju 1.0 — the actual n8n workflow in production
Juju 2.0 replaces the custom RAG layer with MCP-based querying. FieldPulse is migrating its help center to Mintlify, which natively exposes an MCP endpoint — eliminating the need to chunk, embed, and retrieve docs manually. A Confluence MCP connection replaces the manual ingestion pipeline. The Slack bot itself is being rebuilt from n8n's native Slack node to a Node.js + Slack Bolt.js app deployed on Railway for better control over event handling and conversation threading.

Juju 2.0 — simplified MCP-based architecture
The tradeoff is deliberate: Juju 1.0 gave fine-grained control over chunking strategy and reranking. Juju 2.0 trades that control for dramatically less operational surface area. The key question being validated is whether MCP-based retrieval matches or exceeds the 69.2% accuracy baseline from the evaluation cycle.
Outcome
69.2%
Accuracy
~30
Messages / Day
~30 min
Saved / User / Day
3
Teams Using Daily
The system moved internal knowledge from scattered across tabs and teammates to queryable in Slack. The evaluation cycle proved that accuracy was measurable and improvable — and established a concrete benchmark to beat with Juju 2.0.
Next Project
Costbook ETL Pipeline →